 生成AI事件ファイル
生成AI事件ファイル 

本稿は公開時点で確認できた報道・資料をもとに編集しています。内容の正確性には十分配慮しておりますが、その後の続報や公式発表により情報が更新される可能性があります。ご参照の際は、必ず最新の公式情報も合わせてご確認ください。
Transformer完全ガイド:2025年最新版
Attention機構とPositional Encodingの仕組みを徹底解説
初心者〜上級者向け
目次
Transformerは、2017年にGoogleが発表した「Attention Is All You Need」論文で紹介された革命的な深層学習アーキテクチャです。従来のRNNやCNNとは全く異なるアプローチで、現在のChatGPT、BERT、GPT-4などの大規模言語モデルの基盤技術となっています。
本記事では、Transformerの基本概念から最新の応用まで、初心者にも分かりやすく体系的に解説します。特にAttention機構とPositional Encodingという2つの核心技術について詳しく説明し、実際の実装方法まで紹介します。
この記事で学べること
- Transformerの基本原理と革新性
- Attention機構の詳細な仕組み
- Positional Encodingの数学的背景
- BERT、GPT、T5などの主要モデルの違い
- PyTorchを使った実装例
- 2024-2025年の最新技術動向
1. Transformerとは?革命的なアーキテクチャの基礎

出典: Machine Learning Mastery – Transformerアーキテクチャの全体像
1.1 Transformerが解決した課題
従来手法の問題点
- RNN/LSTM: 逐次処理のため学習が遅い
- CNN: 長距離依存関係の捕捉が困難
- 両方: 並列処理が困難
- 勾配消失問題による長系列の処理限界
Transformerの解決策
- 完全並列処理: 高速な学習・推論
- Self-Attention: 長距離依存関係を直接モデル化
- 位置符号化: 系列の順序情報を保持
- 残差接続による勾配問題の解決
1.2 Transformerの基本構造
エンコーダ (Encoder)
Multi-Head Self-Attention
Position-wise Feed Forward
Layer Normalization
Residual Connection
デコーダ (Decoder)
Masked Multi-Head Self-Attention
Multi-Head Cross-Attention
Position-wise Feed Forward
Layer Normalization
重要ポイント: Transformerの革新性は「注意機構(Attention)のみ」でシーケンス処理を行うことです。従来のRNNやCNNは一切使用せず、全ての処理を並列化できるため、大規模データでの学習が劇的に高速化されました。
2. Attention機構の詳細解説
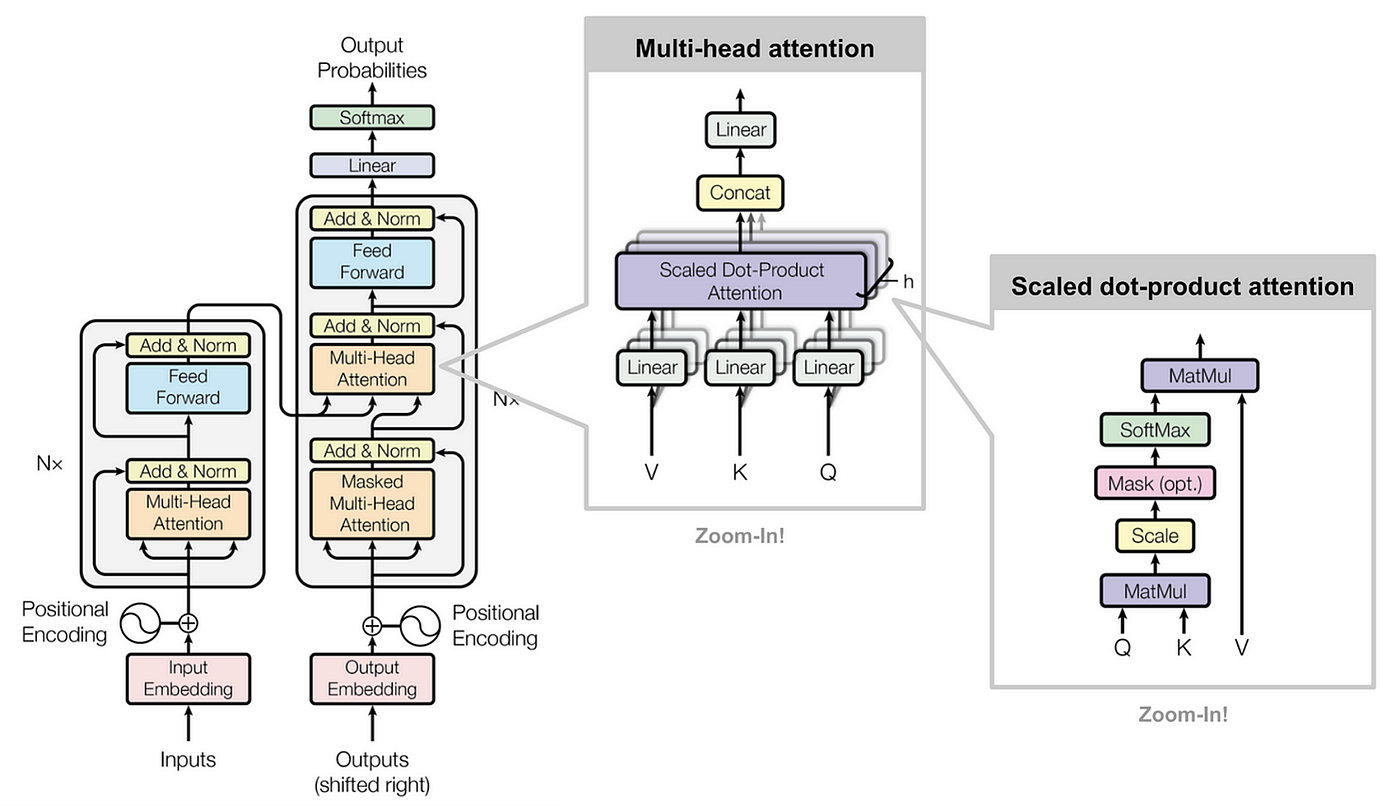
出典: Medium – Self-Attention機構の詳細図解
2.1 Self-Attentionの基本概念
Self-Attention(自己注意機構)は、入力シーケンスの各要素が他の全ての要素とどの程度関連しているかを学習する仕組みです。例えば「私は今日学校に行った」という文では、「私」と「行った」の関係性を直接的にモデル化できます。
Scaled Dot-Product Attentionの数式
Q (Query): 注意を向ける側の表現
K (Key): 注意を向けられる側の表現
V (Value): 実際に取得する情報
d_k: キーベクトルの次元数
2.2 Multi-Head Attentionの仕組み
Head 1: 文法関係
主語と述語の関係性を学習
Head 2: 意味関係
単語間の意味的な関連性を学習
Head 3: 位置関係
単語の位置的な関係を学習
# Multi-Head Attentionの実装例(PyTorch)
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.depth = d_model // num_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, q, k, v, mask=None):
matmul_qk = torch.matmul(q, k.transpose(-2, -1))
dk = torch.tensor(k.shape[-1], dtype=torch.float32)
scaled_attention_logits = matmul_qk / math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = torch.softmax(scaled_attention_logits, dim=-1)
output = torch.matmul(attention_weights, v)
return output, attention_weights2.3 Attentionの可視化と解釈
実例:「The cat sat on the mat」のAttention
| 単語 | The | cat | sat | on | the | mat |
|---|---|---|---|---|---|---|
| cat | 0.1 | 0.4 | 0.3 | 0.1 | 0.05 | 0.05 |
| sat | 0.05 | 0.3 | 0.35 | 0.2 | 0.05 | 0.05 |
数値が大きいほど強い関連性を示します。「cat」は「sat」と強く関連し、「sat」は「on」とも関連することが分かります。
3. Positional Encodingの仕組み
3.1 なぜPositional Encodingが必要なのか?
問題:Attentionは順序を理解できない
Self-Attention機構は各要素間の関係性を学習しますが、要素の順序(位置)情報は含まれていません。例えば以下の2つの文は、Attentionにとって同じに見えてしまいます:
3.2 Sinusoidal Positional Encodingの数式
位置符号化の数式
pos: 単語の位置(0, 1, 2, …)
i: 次元のインデックス
d_model: モデルの次元数(通常512)
3.3 Positional Encodingの特徴
利点
- 固定長: 学習不要で計算効率が良い
- 相対位置: 単語間の距離関係を表現
- 周期性: 長いシーケンスにも対応
- 一意性: 各位置で異なる符号化
応用例
- Learned PE: 学習可能な位置符号化
- Relative PE: 相対位置に特化
- Rotary PE: 回転による位置符号化
- ALiBi: 線形バイアスによる位置符号化
# Positional Encodingの実装例
import numpy as np
import torch
def positional_encoding(seq_len, d_model):
pos = np.arange(seq_len)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
# 角度計算
angles = pos / np.power(10000, (2 * (i // 2)) / d_model)
# sin/cosを適用
angles[:, 0::2] = np.sin(angles[:, 0::2]) # 偶数インデックス
angles[:, 1::2] = np.cos(angles[:, 1::2]) # 奇数インデックス
pos_encoding = torch.tensor(angles, dtype=torch.float32)
return pos_encoding
# 使用例
pe = positional_encoding(seq_len=100, d_model=512)
print(f"Position Encoding shape: {pe.shape}") # [100, 512]
4. BERT vs GPT:アーキテクチャの違い
4.1 基本的な違い
| 項目 | BERT | GPT | T5 |
|---|---|---|---|
| アーキテクチャ | エンコーダのみ | デコーダのみ | エンコーダ-デコーダ |
| 注意方向 | 双方向 | 単方向(左→右) | 双方向+単方向 |
| 主な用途 | 理解タスク | 生成タスク | 変換タスク |
| 事前学習 | MLM + NSP | 次単語予測 | Span Corruption |
| 代表モデル | BERT, RoBERTa | GPT-3, GPT-4 | T5, UL2 |
4.2 BERT:双方向エンコーダ
特徴
- 文全体の文脈を同時に考慮
- Masked Language Model(MLM)で学習
- Next Sentence Prediction(NSP)
- 文書理解に特化
適用分野
- 質問応答システム
- 文書分類
- 感情分析
- 固有表現認識
入力例: “[CLS] 今日は [MASK] 天気です [SEP]”
予測: “良い” (文脈から推測)
4.3 GPT:単方向デコーダ
特徴
- 左から右への順次処理
- 自己回帰的な言語モデル
- 次単語予測で学習
- テキスト生成に特化
適用分野
- 対話システム
- 文章生成
- コード生成
- 翻訳
入力例: “今日は良い天気です。散歩に”
生成: “行きたいと思います。” (続きを生成)
4.4 選択指針
理解タスク
→ BERT系モデルを選択
生成タスク
→ GPT系モデルを選択
変換タスク
→ T5系モデルを選択
5. 実装方法と使い方
5.1 Hugging Face Transformersを使った実装
# 1. 必要なライブラリのインストール
pip install transformers torch datasets
# 2. 基本的な使用例
from transformers import AutoTokenizer, AutoModel
import torch
# モデルとトークナイザーの読み込み
model_name = "bert-base-japanese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# テキストの処理
text = "今日は良い天気です。"
inputs = tokenizer(text, return_tensors="pt")
# 推論実行
with torch.no_grad():
outputs = model(**inputs)
# 結果の取得
last_hidden_states = outputs.last_hidden_state
print(f"Output shape: {last_hidden_states.shape}") # [1, seq_len, hidden_size]5.2 カスタムTransformerの実装
# シンプルなTransformerブロックの実装
import torch
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(TransformerBlock, self).__init__()
self.attention = nn.MultiheadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# Self-attention
attn_output, _ = self.attention(x, x, x)
x = self.norm1(x + self.dropout(attn_output))
# Feed forward
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
# 使用例
d_model = 512
num_heads = 8
d_ff = 2048
seq_len = 10
batch_size = 2
transformer_block = TransformerBlock(d_model, num_heads, d_ff)
x = torch.randn(seq_len, batch_size, d_model)
output = transformer_block(x)
print(f"Output shape: {output.shape}") # [10, 2, 512]5.3 実用的な応用例
テキスト分類
from transformers import pipeline
classifier = pipeline(
"text-classification",
model="nlp-waseda/roberta-base-japanese"
)
result = classifier("この映画は最高でした!")
print(result) # [{'label': 'POSITIVE', 'score': 0.9}]
質問応答
qa_pipeline = pipeline(
"question-answering",
model="cl-tohoku/bert-base-japanese-v2"
)
context = "東京は日本の首都です。"
question = "日本の首都はどこですか?"
answer = qa_pipeline(
question=question,
context=context
)
print(answer['answer']) # "東京"5.4 性能最適化のポイント
最適化テクニック
計算効率化
- Gradient Checkpointing
- Mixed Precision Training
- Dynamic Padding
- Model Parallelism
メモリ最適化
- DeepSpeed ZeRO
- Gradient Accumulation
- Activation Recomputation
- CPU Offloading
6. 2024-2025年の最新動向
6.1 技術的進歩のタイムライン
2024年前半
Mixture of Experts(MoE)の普及
Switch Transformer、GLaM、PaLMなどでMoEアーキテクチャが主流に
2024年中盤
効率的なAttention機構の発展
Flash Attention 2、Ring Attention等による計算効率の大幅改善
2024年後半
マルチモーダルTransformerの進化
GPT-4V、Claude 3、Gemini Ultraなどでテキスト・画像・音声統合処理が実現
2025年予測
長文脈処理の革新
100万トークン以上の超長文脈処理が標準化、RAGとの統合進展
6.2 注目すべき技術革新
計算効率化
- Flash Attention 3: メモリ使用量を90%削減
- Ring Attention: 分散処理による長文脈対応
- Mamba/State Space Models: 線形計算量の実現
- RetNet: 並列・逐次処理の両立
アーキテクチャ革新
- Mixture of Depths: 動的な計算割り当て
- Retrieval-Augmented Generation: 知識ベース統合
- Constitutional AI: 安全性を組み込んだ学習
- Tool-Using Transformers: 外部ツール連携
2025年の展望
Transformerアーキテクチャは単なるNLPモデルから、汎用AIシステムの基盤技術へと進化しています。特に以下の分野での発展が期待されます:
- 科学研究: タンパク質折りたたみ、薬物発見、材料科学
- 創作支援: コード生成、デザイン、音楽制作
- エージェントAI: 自律的なタスク実行、意思決定支援
- エッジデバイス: 軽量化技術による端末での実装
7. よくある質問(FAQ)
Q1: TransformerとRNNの最大の違いは何ですか?
並列処理の可否が最大の違いです。RNNは逐次処理(t-1 → t → t+1)が必要ですが、Transformerは全てのトークンを同時に処理できます。これにより学習時間が大幅に短縮され、長距離依存関係も直接モデル化できます。
Q2: なぜMulti-Head Attentionが必要なのですか?
単一のAttentionでは捉えきれない多様な関係性を学習するためです。例えば、Head1では文法関係、Head2では意味関係、Head3では位置関係といったように、異なる観点からの注意を並列で学習し、それらを統合することでより豊かな表現を獲得できます。
Q3: GPT-4とBERTはどちらが優秀ですか?
タスクによって異なります。文書理解や分類には双方向のBERTが、テキスト生成や対話にはGPT系が適しています。GPT-4は規模が大きく汎用性に優れますが、特定タスクでは専用にファインチューニングしたBERTの方が効率的な場合もあります。
Q4: Transformerを学習させるのに必要な計算資源は?
モデル規模とタスクに依存します。小規模(BERT-base レベル)ならRTX 3080(10GB VRAM)でファインチューニング可能です。大規模モデル(GPT-3レベル)の事前学習には数百〜数千のA100 GPUが必要ですが、推論のみならクラウドサービス(AWS、Google Cloud)で手軽に利用できます。
Q5: 日本語でTransformerを使う場合の注意点は?
トークナイザーの選択が重要です。日本語専用モデル(京都大学のBERT、rinna社のGPT等)を使用するか、多言語対応モデルでも日本語でファインチューニングされたものを選びましょう。また、文字レベル、単語レベル、サブワードレベルのトークン化方式の違いも理解しておく必要があります。
Q6: 今からTransformerを学ぶべき理由は?
Transformerは現代AIの共通言語となっています。NLPだけでなく、画像認識(Vision Transformer)、音声処理、タンパク質解析まで幅広く応用されており、今後10年間は主要技術であり続ける可能性が高いです。また、Hugging Face等のライブラリにより実装・活用が容易になっています。
まとめ
Transformer完全ガイドの要点
技術的理解
- Self-Attention機構による並列処理の実現
- Positional Encodingで位置情報を付与
- Multi-Head Attentionで多様な関係性を学習
- Encoder-Decoderアーキテクチャの柔軟性
実践的応用
- BERT系は理解タスクに最適
- GPT系は生成タスクに最適
- Hugging Faceで簡単実装
- 2024-2025年も技術進化継続
次のステップ
- 実装経験: Hugging Faceのチュートリアルから始める
- 論文読解: 原典「Attention Is All You Need」を精読
- 応用開発: 自分の課題にTransformerを適用
- 最新動向: arXiv、GitHub、技術ブログで情報収集
Transformerは単なる技術ではなく、
人工知能の新たな可能性を切り開く鍵です
継続的な学習と実践を通じて、AI技術の最前線を体験してください
参考文献・出典
論文:
- Vaswani, A., et al. (2017). “Attention Is All You Need” – https://arxiv.org/abs/1706.03762
- Devlin, J., et al. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
- Radford, A., et al. (2019). “Language Models are Unsupervised Multitask Learners”
技術解説:
- Machine Learning Mastery – Transformer Architecture: https://machinelearningmastery.com/the-transformer-model/
- Jay Alammar – The Illustrated Transformer: https://jalammar.github.io/illustrated-transformer/
- AI NOW – Transformerの仕組み解説: https://ainow.ai/
実装リソース:
- Hugging Face Transformers: https://huggingface.co/transformers/
- PyTorch Tutorials: https://pytorch.org/tutorials/

